3.5. A lemezek szervezése
Az állománynév a legkisebb szervezési egység, amin keresztül a FreeBSD képes megtalálni az állományokat. Az állományok neveiben a kis- és nagybetűt megkülönböztetjük, tehát a readme.txt és a README.TXT elnevezés két különböző állományra utal. A FreeBSD nem az állományok kiterjesztése (ami a konkrét példánkban a .txt volt) alapján dönti el, hogy az adott állomány vajon program, dokumentum vagy valamilyen más fajtájú adat.
Az állományok könyvtárakban tárolódnak. Egy könyvtár lehet akár üres (nincs benne egyetlen állomány sem), vagy többszáz állományt is tartalmazhat. Egy könyvtár ráadásul további könyvtárakat is tárolhat, és így az egymásban elhelyezkedő könyvtárak segítségével könyvtárak egy hierarchiáját tudjuk felépíteni. Ezzel sokkalta könnyebben szervezhetővé válnak az adataink.
Az állományokat és könyvtárakat úgy tudunk elérni, ha megadjuk az állomány vagy a könyvtárt tároló könyvtár nevét, amit egy perjel, a / követ, valamint így összefűzve az eléréshez szükséges további könyvtárak felsorolása. Tehát, ha van egy ize nevű könyvtárunk, amelyben található egy mize könyvtár, amelyen belül pedig egy readme.txt, akkor ennek az állománynak a teljes neve, vagy másképpen szólva az elérési útja ize/mize/readme.txt lesz.
A könyvtárak és az állományok egy állományrendszerben tárolódnak. Minden állományrendszer pontosan egy könyvtárat tartalmaz a legfelső szintjén, amelyet az adott állományrendszer gyökérkönyvtárának nevezünk. Ez a gyökérkönyvtár tartalmazhat aztán további könyvtárakat.
Eddig még valószínűleg minden nagyon hasonló a más operációs rendszerekben tapasztalható fogalmakhoz. Azonban adónak különbségek: például az MS-DOS® a \ jellel választja el az állományok és könyvtárak neveit, miközben a Mac OS® erre a : jelet használja.
A FreeBSD az elérési utakban sem betűkkel, sem pedig semmilyen más névvel nem jelöli meg a meghajtókat. Tehát a FreeBSD-ben nem írhatjuk, hogy a c:/ize/mize/readme.txt.
Helyette az egyik állományrendszert kijelölik gyökér állományrendszernek. A gyökér állományrendszer gyökérkönyvtárára hivatkoznak később / könyvtárként. Ezután minden más állományrendszert a gyökér állományrendszerhez csatlakoztatunk. Ennek értelmében nem számít, hogy a mennyi lemezünk is van a FreeBSD rendszerünkben, hiszen minden könyvtár egyazon lemez részeként jelenik meg.
Tegyük fel, hogy van három állományrendszerünk, hívjuk ezeket A-nak, B-nek és C-nek. Minden állományrendszer rendelkezik egy gyökérkönyvtárral, amely két további könyvtárat tartalmaz: A1-et és A2-t (és ennek megfelelően a többi B1-et és B2-t, valamint C1 és C2-t).
Nevezzük A-t a gyökér állományrendszernek. Ha a könyvtár tartalmának megjelenítéséhez most kiadnánk az ls parancsot, két alkönyvtárat látnánk, az A1-et és A2-t. A létrejött könyvtárfa valahogy így nézne ki:
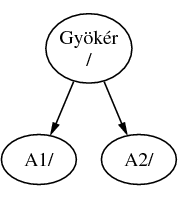
Egy állományrendszert csak egy másik állományrendszer valamelyik könyvtárába tudunk csatlakoztatni. Ezért most tételezzük fel, hogy a B állományrendszert az A1 könyvtárba csatlakoztatjuk. Ezután a B gyökérkönyvtára átveszi a A1 helyét az állományrendszerben, és ennek megfelelően megjelennek a B könyvtárai is:

A B1 vagy B2 könyvtárakban található állományok bármelyike innentől kezdve a /A1/B1, illetve a /A1/B2 elérési utakon érhetőek el. Az A1 könyvtárban található állományok erre az időre rejtve maradnak. Akkor fognak újra felbukkanni, ha a B állományrendszert leválasztjuk az A állományrendszerről.
Ha a B állományrendszert az A2 könyvtárba csatlakoztatnánk, az iménti ábra nagyjából így nézne ki:
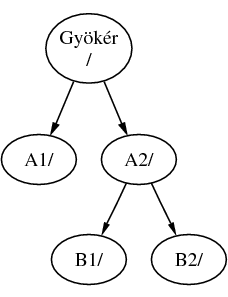
és ennek megfelelően az előbb tárgyalt elérési utak /A2/B1 és /A2/B2 lennének.
Az állományrendszerek egymáshoz is csatlakoztathatóak. A példát ennek megfelelően úgy is folytathatjuk, hogy a C állományrendszert csatlakoztatjuk B állományrendszerben található B1 könyvtárhoz. Ennek eredménye a következő elrendezés lesz:
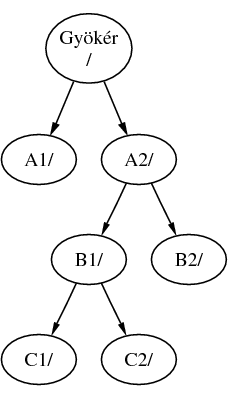
Vagy a C állományrendszer az A1 könyvtáron keresztül csatlakoztatható akár közvetlenül az A állományrendszerhez is:

Az MS-DOS operációs rendszert ismerők számára ez hasonló lehet a join parancshoz (habár teljesen nem egyezik meg vele).
Általában azonban ezzel nem kell törődnünk, hiszen többnyire csak a FreeBSD telepítése során hozunk létre állományrendszereket és választjuk meg a csatlakozási pontjukat. A későbbiekben legfeljebb ez akkor kerül elő ismét, amikor újabb lemezeket adunk hozzá a rendszerhez.
Teljességgel megengedhető, hogy elhagyjuk a többit és csak egyetlen óriási gyökérállományrendszert használjunk. Ennek viszont megvannak a maga hátrányai és az egyetlen előnye.
Több állományrendszer használatának előnyei
A különböző állományrendszereknek különböző csatlakoztatási beállításai (mount options) lehetnek. Például, ha kellően elővigyázatosak akarunk lenni, a gyökérállományrendszer írásvédett módon is csatlakoztatható, aminek köszönhetően lehetetlenné válik a rendszer számára fontos állományok véletlen törlése vagy felülírása. Ha elkülönítjük a felhasználók számára írható állományrendszereket (például a /home könyvtárakat) a többi állományrendszertől, lehetővé válik számunkra, hogy nosuid beállítással csatlakoztassuk ezeket. Ez a beállítás megakadályozza, hogy ezekben a suid/guid bitekkel rendelkező végrehajtható állományok használhatóak legyenek, ezáltal növeli a rendszer biztonságosságát.
A FreeBSD az állományrendszer használatától függően magától határoz a benne található állományok optimális kiosztását illetően. Így tehát a gyakorta módosított, kisebb állományokat tartalmazó állományrendszerek esetén teljes más technikákat alkalmaz, mint például a nagyobb, kevésbé változó állományok esetén. Azonban egyetlen állományrendszer használatával ez a gyorsítási módszer odavész.
Noha a FreeBSD állományrendszerei nagyon jól tűrik a hirtelen áramkimaradásokat, egy döntő ponton bekövetkező váratlan leállás továbbra is kárt okozhat a szerkezetükben. Ha azonban több állományrendszerre osztjuk a tárolandó adatainkat, sokkal valószínűbbé válik, hogy egy ilyen eset után a rendszerünk talpra tud állni, és szükség esetén nekünk is könnyebb lesz a biztonsági mentéseinkből helyreállítani a sérült állományokat.
Egyetlen állományrendszer használatának előnyei
Az állományrendszerek mérete rögzített. Miután a FreeBSD telepítése során létrehoztunk egy adott méretű állományrendszert, előfordulhat, hogy később szükségünk lesz a méretének növelésére. Ilyenkor nehezen kerülhetjük el az ilyenkor szokásos teendőket: biztonsági mentés készítése, az új méretnek megfelelő állományrendszer létrehozása, majd ezután a lementett adataink visszaállítása.
Fontos: A FreeBSD-ben azonban megtalálható a growfs(8) parancs, amelynek segítségével az állományrendszerek mérete használat közben növelhető, és ezzel megszűnik a méretre vonatkozó korlátozás.
Az állományrendszerek partíciókban tárolódnak. A FreeBSD UNIX®-os eredete miatt azonban ez a kifejezés nem a hétköznapi “partíció” jelentését takarja (mint például egy MS-DOS partíció). Minden partíciót egy betű azonosít a-tól h-ig. Mindegyik partíció csak egyetlen állományrendszert tartalmazhat, aminek révén az állományrendszereket vagy az állományrendszerek hierarchiájában található csatlakozási pontjukkal vagy pedig az ezeket tartalmazó partíció betűjével azonosíthatjuk.
A FreeBSD ezeken felül külön lemezterülen tárolja a lapozóállományt (swap space). A lapozóállományt használja a FreeBSD virtuális memória (virtual memory) megvalósításához. Ennek köszönhetően a számítógép képes úgy viselkedni, mintha jóval több memóriával rendelkezne, mint valójában. Így, amikor a FreeBSD kifogy a memóriából, egyszerűen kirakja a memóriából a lapozóállományba az éppen nem használt adatokat, majd amikor ismét szüksége lesz rájuk, visszatölti ezeket (és ilyenkor megint kirak valami mást).
Némely partícióhoz kötődnek bizonyos megszokások.
| Partíció | Megszokás |
|---|---|
| a | Általában ez tartalmazza a gyökér állományrendszert. |
| b | Általában ez tartalmazza a lapozóállományt. |
| c | Mérete általában a tartalmazó slice méretével egyezik meg. Ennek köszönhetően a segédprogramok (például egy hibás szektorokat kereső program) a c partíción keresztül képesek akár az egész slice-al dolgozni. Normális esetben ezen a partíción nem hozunk létre állományrendszert. |
| d | A d partícióhoz egykoron kapcsolódott különleges jelentés, azonban mostanra ez már megszűnt, és a d egy teljesen átlagos partíciónak tekinthető. |
Minden állományrendszert tartalmazó partíciót a FreeBSD egy ún. slice-ban tárol. A FreeBSD számára a slice elnevezés utal mindarra, amit általában partíciónak neveznek, és ismét megemlítjük, mindez a UNIX-os eredet miatt. A slice-okat 1-től 4-ig sorszámozzák.
A slice-ok sorszáma 1-től indulva az eszközök neve után egy s betűvel elválasztva következik. Így tehát a “da0s1” jelentése az első slice lesz az első SCSI-meghajtón. Lemezenként négy fizikai slice hozható létre, de ezeken belül tetszőleges típusú logikai slice-ok helyezhetőek el. Ezen további slice-ok sorszámozása 5-től kezdődik, így ennek megfelelően a “ad0s5” lesz az első IDE-lemezen található első kiterjesztett slice. Ezeket az eszközöket foglalják el a különböző állományrendszerek.
A slice-ok, a “veszélyesen dedikált” (Dangerously Dedicated) fizikai meghajtók, és minden más olyan meghajtó, amely partíciókat tartalmaz, a-tól h-ig jelölődnek. Ez a betű az eszköz neve után következik, így ennek megfelelően a “da0a” lesz az első “da” meghajtó “a”, vagyis a “veszélyesen dedikált” partíciója. Az “ad1s3e” lesz a második IDE-lemezmeghajtón a harmadik slice-ban szereplő ötödik partíció.
Végezetül, a rendszerben minden lemezt azonosítunk. A lemez neve a típusára utaló kóddal kezdődik, amely után aztán egy sorszám jelzi, hogy melyik lemezről is van szó. Azonban eltérően a slice-okétól, a lemezek sorszámozása 0-tól indul. Az általánosan elterjedt kódolások a 3-1 Táblázatban találhatóak.
Amikor hivatkozunk egy partícióra, a FreeBSD elvárja tőlünk, hogy nevezzük meg az adott partíciót tartalmazó slice-ot és lemezt is. Emiatt egy partícióra mindig úgy hivatkozunk, hogy először megadjuk a tartalmazó lemez nevét, ettől s-sel elválasztva a tartalmazó slice sorszámát, majd ezt a partíció betűjelével zárjuk. Erre példákat a 3-1 Példaban láthatunk.
Az érhetőség kedvéért a 3-2 Példa bemutatja egy lemez kiosztásának fogalmi sablonját.
A FreeBSD telepítéséhez először be kell állítani a lemezen található slice-okat, majd létrehozni benne a FreeBSD-hez használni kívánt partíciókat, kialakítani rajtuk az állományrendszereket (vagy a lapozóállományt) és eldönteni, melyik állományrendszert kívánjuk csatlakoztatni.
Táblázat 3-1. Lemezes eszközök kódjai
| Kód | Jelentés |
|---|---|
| ad | ATAPI (IDE) lemez |
| da | közvetlen hozzáférésű SCSI lemez |
| acd | ATAPI (IDE) CDROM |
| cd | SCSI CDROM |
| fd | Floppylemez |
Példa 3-2. Egy lemez kialakításának sablonja
Az ábrán a rendszerhez csatlakoztatott első IDE-lemez látható a FreeBSD szemszögéből. Tegyük fel, hogy ez a lemez 4 GB méretű és két, egyenként 2 GB méretű slice-ot (avagy MS-DOS partíciót) tartalmaz. Az első slice egy MS-DOS formátumú lemezt foglal magában, a C: meghajtót, illetve a második slice egy telepített FreeBSD-t tartalmaz. Ebben a példában a FreeBSD három adatot és egy lapozóállományt tároló partícióval rendelkezik.
A három partíció mindegyikén találhatunk egy-egy állományrendszert. Az a partíció lesz a gyökér állományrendszer, az e lesz a rendszerünkben a /var és az f pedig a /usr könyvtár.
