3.5. Organizacja dysku
Najmniejszą jednostką organizacji dysku używaną przez FreeBSD do odnajdywania plików jest nazwa pliku. W nazwach plików rozróżniane są duże i małe litery, tak więc readme.txt i README.TXT to dwa różne pliki. FreeBSD nie wykorzystuje rozszerzeń nazw plików (.txt) do określenia, czy plik jest programem, dokumentem, czy innym zbiorem danych.
Pliki przechowywane są w katalogach. Katalog może być pusty, lub może zawierać setki plików. Może również zawierać inne katalogi, dzięki czemu mamy możliwość zbudowania hierarchicznej struktury katalogów. Pozwala to na łatwą organizację danych.
Dostęp do plików i katalogów uzyskuje się podając nazwę pliku lub katalogu, poprzedzoną ukośnikiem / i innymi wymaganymi nazwami katalogów. Jeśli mamy katalog foo, a w nim katalog bar, w którym znajduje się plik readme.txt, wówczas pełną nazwą, bądź ścieżką dostępu do pliku jest foo/bar/readme.txt.
Katalogi i pliki przechowywane są w systemie plików. Każdy system plików ma jeden katalog najwyższego poziomu, zwany katalogiem głównym systemu plików. W katalogu głównym mogą być umieszczone następne katalogi.
To, o czym mówimy, jest zapewne podobne do innych systemów operacyjnych, z którymi być może zetknęliśmy się wcześniej. Są jednak różnice; na przykład w systemie MS-DOS® nazwy plików i katalogów oddzielane są znakiem \, w Mac OS® natomiast znakiem :.
We FreeBSD nie są używane litery dysków, lub inne nazwy dysków w ścieżce. Nie spotkamy się w FreeBSD z czymś takim jak c:/foo/bar/readme.txt.
Jest natomiast jeden system plików pełniący rolę głównego systemu plików. Zawiera on katalog główny dostępny jako /. Każdy inny system plików jest montowany w głównym systemie plików. Niezależnie od tego, ile dysków mamy w komputerze, we FreeBSD każdy katalog wydaje się być częścią tego samego dysku.
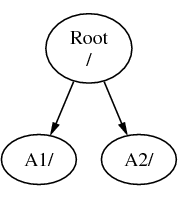
Załóżmy, że mamy trzy systemy plików, nazwane A, B i C. Każdy z nich ma katalog główny, zawierający dwa katalogi o nazwach A1, A2 (oraz odpowiednio B1, B2 i C1, C2).
Niech A będzie głównym systemem plików. Gdybyśmy sprawdzili jego zawartość poleceniem ls, zobaczylibyśmy dwa podkatalogi A1 i A2. Drzewo katalogów wygląda następująco:
System plików musi być montowany w katalogu innego systemu plików. Przyjmijmy teraz, że montujemy system plików B w katalogu A1. Główny katalog B zastąpi A1, a podkatalogi B pojawią się w odpowiednim miejscu:
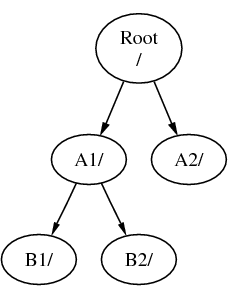
Do plików znajdujących się w katalogach B1 i B2 można się dostać posługując się ścieżką /A1/B1 lub /A1/B2. Pliki poprzednio obecne w katalogu /A1 są tymczasowo ukryte. Pojawią się ponownie po odmontowaniu B z A.
Gdyby zamontować B w A2, drzewo katalogów wyglądałoby tak:
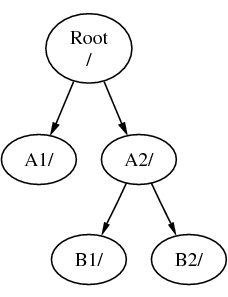
ścieżki natomiast miałyby postać /A2/B1 i /A2/B2.
Systemy plików mogą być montowane jeden na drugim. Rozwijając poprzedni przykład, możemy zamontować system plików C w katalogu B1 systemu plików B, otrzymując następującą postać drzewa katalogów:
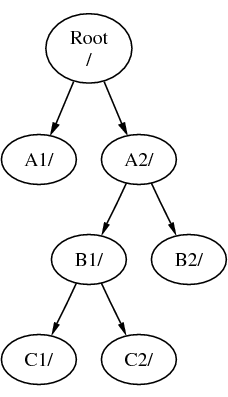
Można równie dobrze zamontować C bezpośrednio w systemie plików A, w katalogu A1:
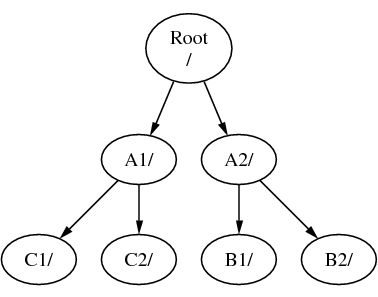
Znającym system MS-DOS może to przypominać polecenie join, choć nie jest to to samo.
Zwykle nie trzeba zajmować się opisanymi powyżej rzeczami. Najczęściej tworzymy systemy plików podczas instalacji FreeBSD, wybieramy miejsce ich zamontowania i nie wprowadzamy później żadnych zmian, chyba, że zainstalujemy nowy dysk.
Można utworzyć jeden obszerny główny system plików i nie tworzyć żadnych innych. Takie podejście ma kilka wad i jedną zaletę.
Korzyści z kilku systemów plików
-
Odrębne systemy plików mogą mieć różne opcje montowania (mount options). Na przykład, przy odpowiednim przygotowaniu, główny system plików może być zamontowany tylko do odczytu, przez co niemożliwe będzie przypadkowe usunięcie lub zmiana ważnego pliku. Oddzielenie systemów plików dostępnych do zapisu dla użytkowników, jak np. /home, od innych pozwala również na montowanie ich z opcją nosuid; co z kolei pozwala zwiększyć bezpieczeństwo systemu uniemożliwiając wykorzystanie bitów suid/guid.
-
FreeBSD automatycznie optymalizuje układ plików w systemie plików, w zależności od tego, jak ów system jest wykorzystywany. System plików zawierający wiele często zapisywanych małych plików będzie optymalizowany inaczej niż taki, w którym przechowywane jest mniej plików o dużych rozmiarach. W przypadku jednego dużego systemu plików taka optymalizacja nie zadziała.
-
Systemy plików FreeBSD są odporne na awarie zasilania. W niesprzyjających okolicznościach może się jednak zdarzyć, że przerwa w dostawie prądu w krytycznym momencie spowoduje uszkodzenie struktury systemu plików. Przechowywanie danych w kilku systemach plików zwiększa szansę, że system uruchomi się ponownie, dzięki czemu łatwiej będzie odzyskać dane z kopii zapasowej.
Korzyść z pojedynczego systemu plików
-
Systemy plików mają stały rozmiar. Podczas instalacji FreeBSD tworzymy system plików o zadanym rozmiarze; później może się okazać, że trzeba powiększyć partycję. Niełatwo jest to zrobić inaczej, niż przez przygotowanie zapasowej kopii danych, utworzenie na nowo systemu plików o większych rozmiarach, oraz skopiowanie danych z powrotem.
WAŻNE: We FreeBSD dostępne jest polecenie growfs(8), które pozwala na zwiększenie rozmiaru systemu plików w locie, pomijając wspomniane ograniczenie.
Systemy plików przechowywane są na partycjach. Pojęcie partycji ma tu inne znaczenie niż popularnie stosowane (np. partycja systemu MS-DOS), ze względu na uniksowy rodowód FreeBSD. Każda z partycji oznaczana jest literą, od a do h. Pojedyncza partycja może zawierać jeden system plików, dlatego też do systemów plików często odwołuje się albo poprzez miejsce ich zamontowania w głównym systemie plików, albo przez literowe oznaczenie partycji, na której dany system plików się znajduje.
Przestrzeń dyskowa jest również używana we FreeBSD jako przestrzeń wymiany, pełniąc w ten sposób rolę pamięci wirtualnej. Komputer może dzięki temu dysponować większą ilością pamięci, niż ma w rzeczywistości. Kiedy pamięci zaczyna brakować, FreeBSD odsyła niektóre nieużywane dane do przestrzeni wymiany, a gdy znów okażą się potrzebne, przenosi je z powrotem (odsyłając jednocześnie inne dane).
Z niektórymi partycjami związane są pewne konwencje dotyczące ich zastosowania./para>
| Patrycja | Konwencja |
|---|---|
| a | Zwykle zawiera główny system plików |
| b | Zwykle zawiera przestrzeń wymiany |
| c | Zwykle jest tego samego rozmiaru, co obejmujący ją segment. Dzięki temu programy działające na całym segmencie (na przykład wykrywające uszkodzone obszary dysku) mogą działać na partycji c. Zwykle nie tworzy się na tej partycji systemu plików. |
| d | Swego czasu partycja d miała specjalne znaczenie, obecnie już go nie ma. Do dziś jednak niektóre programy mogą dziwnie się zachowywać, jeśli każe im się pracować na partycji d, dlatego też sysinstall zwykle w ogóle jej nie tworzy. |
Każda partycja zawierająca system plików przechowywana jest na czymś, co we FreeBSD nosi nazwę segmentu. Jest to określenie tego, co wcześniej zwane było partycją, i ponownie jest to konsekwencją uniksowych korzeni FreeBSD. Segmenty są oznaczane liczbami od 1 do 4.
Numery segmentów, wraz z przedrostkiem s, poprzedzone są nazwą urządzenia. Tak więc “da0s1” jest pierwszym segmentem na pierwszym dysku SCSI. Na dysku mogą być najwyżej cztery fizyczne segmenty, można jednak tworzyć segmenty logiczne wewnątrz segmentów fizycznych specjalnego typu. Powstałe w ten sposób segmenty rozszerzone mają numery od 5 wzwyż, zatem “ad0s5” odpowiada pierwszemu rozszerzonemu segmentowi na dysku IDE. Urządzenia te są wykorzystywane przez systemy plików, które zajmują cały segment.
Segmenty, dyski “niebezpiecznie dedykowane” i inne dyski zawierają partycje, oznaczane literami od a do h. Litera dopisywana jest do nazwy urządzenia, więc “da0a” odpowiadać będzie partycji a na pierwszym dysku da, “niebezpiecznie dedykowanym”. Z kolei “ad1s3e” oznacza piątą partycję w trzecim segmencie drugiego dysku IDE.
Własne oznaczenie ma także każdy dysk. Nazwa dysku składa się z symbolu określającego typ dysku, oraz numeru, określającego który to dysk. Dyski, inaczej niż segmenty, numerowane są od zera. Tabela 3-1 zawiera najczęściej spotykane zwykle oznaczenia.
Gdy odwołujemy się do partycji, FreeBSD wymaga, byśmy podali również nazwę obejmującego ją segmentu i dysku. Z kolei gdy odwołujemy się do segmentu, podajemy również nazwę dysku. Kolejno podajemy więc nazwę dysku, s, numer segmentu, a na koniec literę partycji; patrz Przykład 3-1.
Przykład 3-2 pokazuje schematyczny model dysku, z pomocą którego łatwiej będzie zrozumieć pewne rzeczy.
Gdy instalujemy FreeBSD, w pierwszej kolejności musimy przygotować segmenty na dysku, następnie w segmencie przeznaczonym dla FreeBSD utworzyć partycje, następnie wewnątrz partycji stworzyć system plików (lub przestrzeń wymiany) i określić miejsce jego montowania.
Tabela 3-1. Oznaczenia dysków
| Oznaczenie | Znaczenie |
|---|---|
| ad | Dysk ATAPI (IDE) |
| da | Dysk SCSI o dostępie bezpośrednim |
| acd | CDROM ATAPI (IDE) |
| cd | CDROM SCSI |
| fd | Stacja dyskietek |
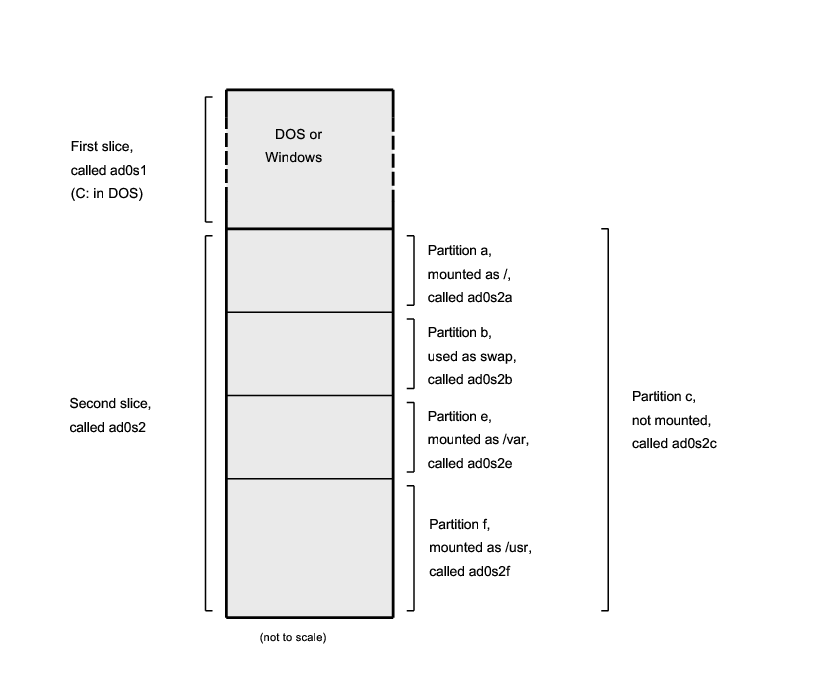
Przykład 3-2. Schematyczny model dysku
Rysunek przedstawia pierwszy dysk IDE z punktu widzenia FreeBSD. Zakładamy, że dysk ma rozmiar 4 GB i jest podzielony na dwa segmenty (partycje w MS-DOS) o rozmiarze po 2 GB. Pierwszy segment zawiera DOS-owy dysk C:, natomiast w drugim segmencie znajduje się przykładowa instalacja FreeBSD, z trzema partycjami oraz partycją wymiany.
Każda z trzech partycji przechowuje system plików. Na partycji a umieszczony jest główny system plików, na e znajduje się katalog /var, a na f katalog /usr.